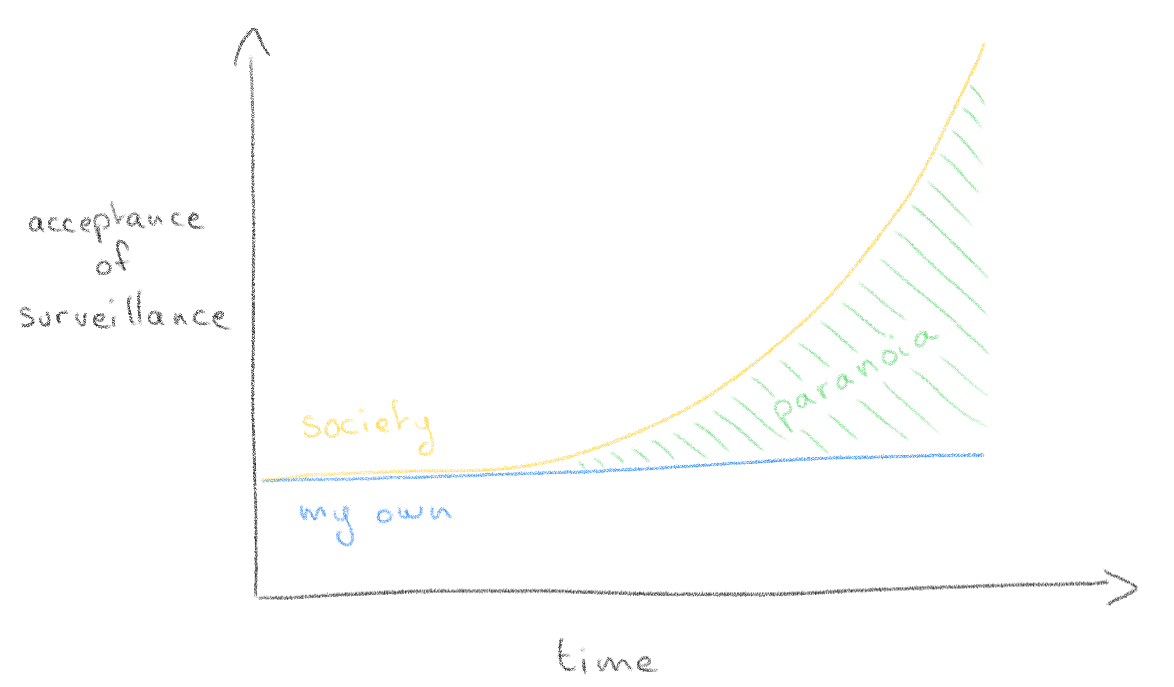
Relinquish your own thoughts
Slowly but surely, we are foregoing self agency to algorithms.
2019 Gmail settings:
Web Omnipresence with Docker, VPN & Squid proxying
Here’s a method for having several browser windows proxying through several countries concurrently.
Demo
Working Principle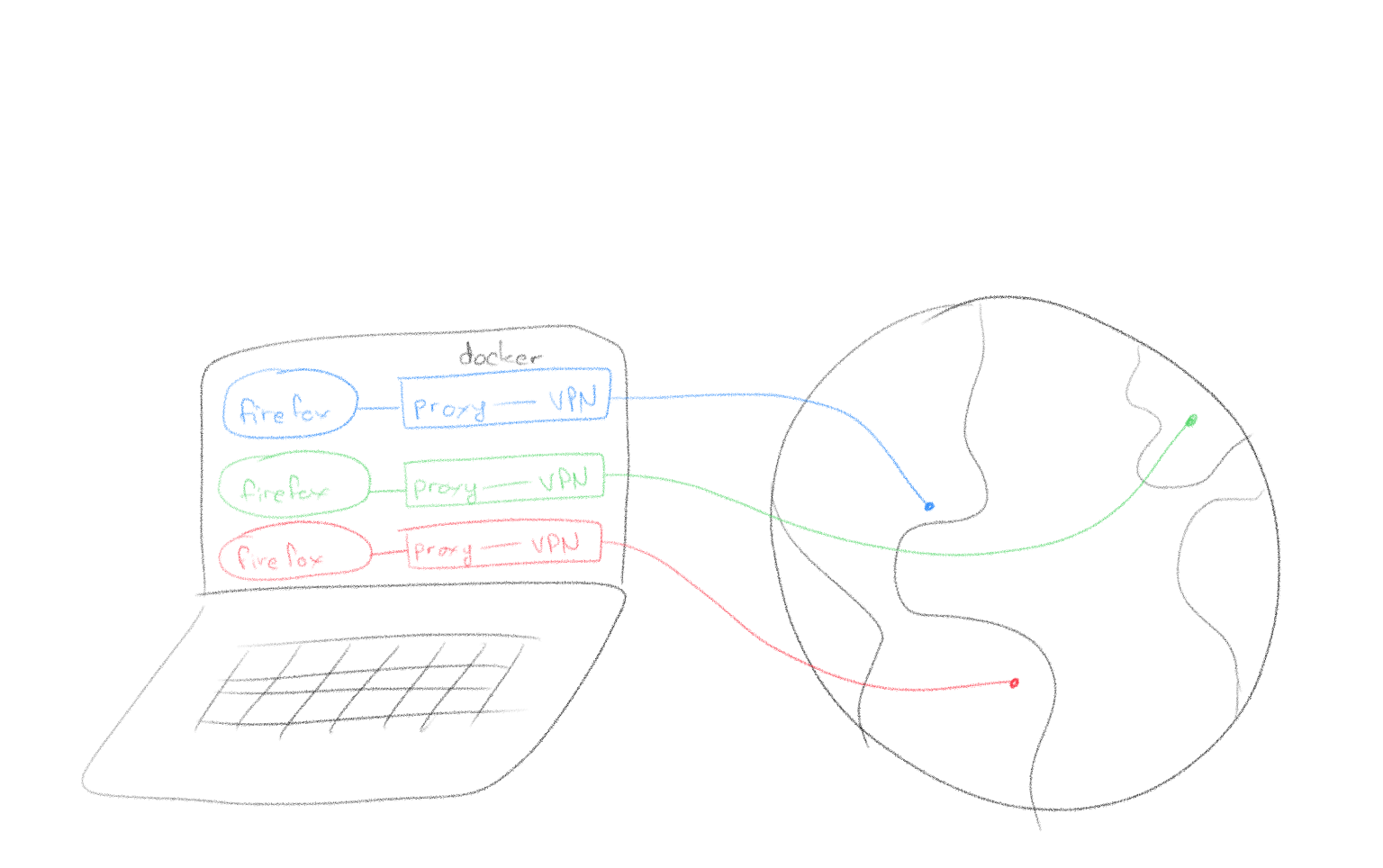
Requirements
- a VPN service supporting OpenVPN as a client (this example uses vpntunnel)
- Docker
- Firefox
- MacOS isn’t a requirement per se but this guide & accompanying scripts are written for it.
Setup Steps
- Download this package containing Dockerfile build instructions & some scripts.
- Populate the directory “openvpn_config_files/” with the ovpn files from the VPN service you use.
- Edit the script called “vpn” and replace <VPN_SERVICE_USERNAME> and <VPN_SERVICE_PASSWORD> with your username and password.
- Run with “./omnipresence.sh <name_of_ovpn_file>”